The non-deniable truth of our profession is that somewhere along the way any development or manufacturing process will have its issues. Your suspicions should be raised when you hear engineers say something like “we did not encounter any problems and everything was perfect”. If there was not even one problem along the way it is because either it had yet to be found or that there is a confidentiality issue that prevents them from revealing the problems they encountered.
From my personal experience it’s not that I did not have a perfect run but that’s up to a point. When the system is complex enough with many subsystems things may shift sideways in each and every step of the product life cycle. Sometimes it is a small glitch that takes 15 minutes to sort out and sometimes it is a showstopper that puts the entire project at risk.
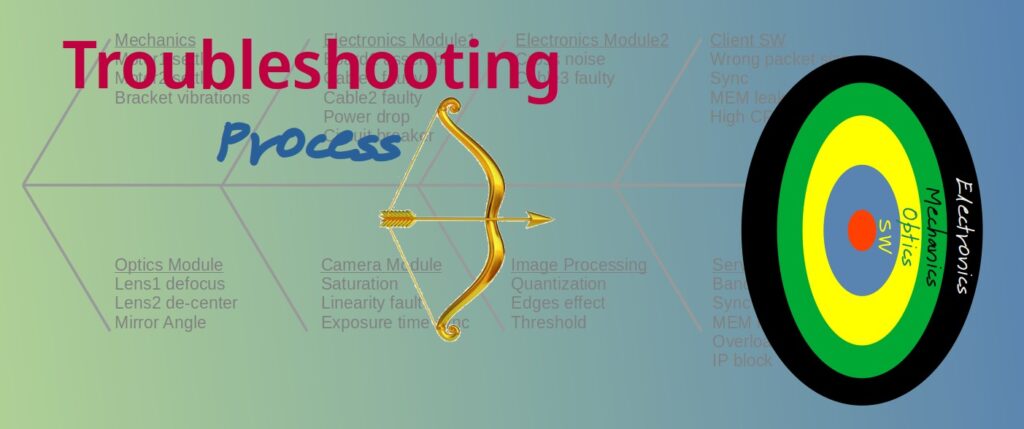
We must accept that troubleshooting is an inseparable part of our profession. Let’s have a closer look at it as a process and like any other development/ manufacturing processes let’s analyze what makes it a better process and where the pitfalls are.
The “N Steps” Troubleshooting Methodology
Over the years I have been introduced to many “N Steps” troubleshooting methodologies where N is an integer between 5 and 8. Each organization has its own version of methodology and they are essentially all the same.
In this post I will detail my own best practice version of 6 Steps with some “mini-steps” in between to be used only in specific cases. This methodology is based on the famous 7-steps with a few caveats.
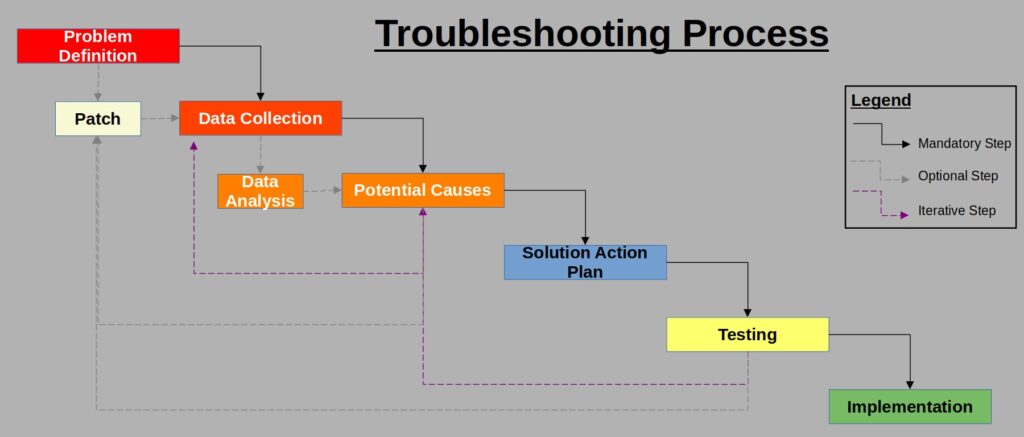
1. Problem Definition
The most important thing in troubleshooting is having a clear definition what the problem is, for example: “the furnace temperature reaches 250oC instead of 350oC”, “the database downtime for daily indexing takes more than 5 minutes”, “the motor halts after running 5 seconds in 75% duty cycle” and so on.
We do not always know the exact details of the problem as to be able to define it that well so, the first task is clearly to say what’s bothering us and specifically what triggered our belief that something was wrong and narrow it down to what exactly we consider as the problem.
One very important thing to note is what the source of the problem discovery is. Let’s divide the potential sources into 3: internally, externally from a 3rd party and client complaint.
In the case of internal sources, discovery may arrive from many disciplines in the organization: engineering, research, product, application and even management (yes, I had a CEO that was calling us at the NOC at 2AM to tell us that a web-server was down).
Internal sources are very reliable since they know exactly what the expected behavior of the system is and accordingly, their input will be as accurate as one would expect it to be.
Be aware though that sometimes, false alarms are raised by internal sources – mainly in the cases where the intended uses and the actual uses of the system differ. In such cases we may raise the alarm for something that perhaps on paper is a problem but does not really interfere with the correct and smooth flow of the system.
External sources like test laboratories, service providers and so on are very easy to handle in terms of problem definition: their input will be very accurate and in most times they will define exactly what’s wrong.
For example, if we have a 3rd party testing the data-flow bandwidth we provide our clients, their problem statement will be something like “the bandwidth is 7Gb/s instead of the expected 10Gb/s” which is numeric and very comfortable as a starting point for the troubleshooting process. Another example could be a report from a safety testing laboratory that indicates there is a leakage current of such and such Amperes. Numeric and to the point.
Client complaints are the most difficult to handle. When it comes to client complaints, we must first answer the question “is it a bug or a feature?”. I am quite sure that if a client complains that his car cannot reach the speed of Mach2 there’s nothing wrong with the car. If the client’s complaint turns out to be a real problem, which it is in most cases, then we have to, as previously mentioned, take his complaint and define it as accurately as possible.
However, if the client complains about his car speed limit it means that he expected the car to reach Mach2. In cases such as this, where it is indeed a feature and not a bug, it is up to the Product management of the Project management to decide whether that is something the team should engage and in any case it is outside the troubleshooting process – it becomes a development process.
1.5. Patch
This is definitely not an official step in any of the “N steps” methodologies however it is common practice that happens mainly in the cases where the problem directly affects clients or client experience or when the problem is in application where downtime is of high importance like production lines, FABs, online services or servers etc.
In these cases, regardless of the need of finding the problem and fixing it, there is an urgent need for the field to find some kind of an interim solution so as to enable the client to keep his operation running. This is a terrible task which is done literally at gunpoint aimed at our heads where, most likely, all eyes are on us. Furthermore, patching has its own evolution as the troubleshooting process progresses.
In no less than 100% of the cases the team responsible for the troubleshooting will be the same team responsible to provide the patch. Once we have that in mind, we must insert this step into our “N steps” process, because like it or not, we will have this task on our table and it will consume all of our available troubleshooting resources.
2. Data Collection
In order to analyze and identify the problem we must have relevant data.
Data collection takes time and resources so, it is advisable to have a list of the data required according to its priority and urgency to lead us to the root cause as quickly as possible.
You have to make sure the resources (HW, SW and HR) are available for the data collection you have planned according to the priority of this troubleshooting compared to other tasks the team is involved in.
Furthermore, in a lot of cases the data collection is not entirely in our control for instance, if the data source system is already in the field. Special testing requires machine downtime, a phrase all clients do not want to hear. Some clients do not allow data getting out of their facility without higher-management approval which may also pose issues in obtaining the data. Moreover, if an actual person has to approach the machine and operate it in special conditions it is also an obstacle to take into account.
Try to collect as much data in-house without disturbing the client. Since your client is already angry with you, do not give him more reasons to search for another vendor.
See example data collection table below.
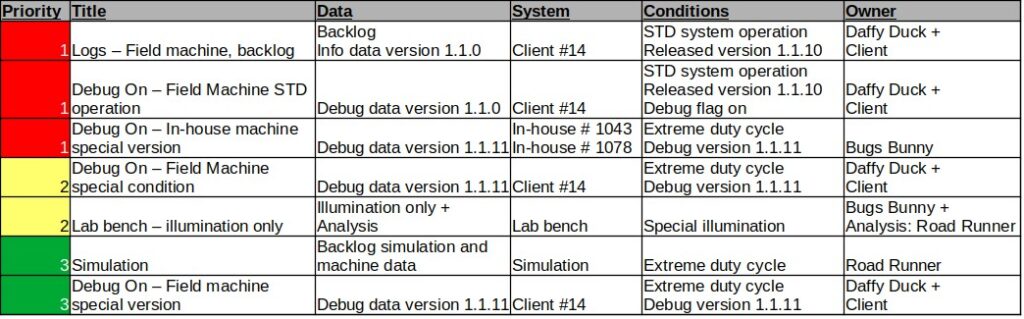
Remember, very much like Schrödinger’s cat, that the data collection by-itself may impact the results of the test. I once had a case of a problematic sync between two SW modules that was eliminated when turning the debug flag on because the debug writing operation caused exactly the delay that prevented the sync issue from re-occurring. Each data collection and experiment should be planned and executed with great care to maintain the data integrity.
2.5. Data Analysis
In special cases having the data available is not enough – we need the data analyzed more profoundly than just simply putting it on a graph and show it to the team.
In these cases we need to locate the right people to perform the analysis and more importantly add the overhead of the data analysis into the timeline of the troubleshooting process. BTW, simulation is also in the loop of data collection \ data analysis.
3. Brainstorm for Potential Causes
Very much like the “differential diagnosis” we see in every episode of the TV series House M.D., now is the time to raise all the possible causes that may cause our problem according to our problem definition and start either ruling them out or sort them out according to their likelihood.
In this particular step the data presentation method as in how exactly we present our existing data is crucial. I will dedicate a post for data presentation since it is a very important aspect in our business.
Very often in this step we realize that some data is missing and we get back to data collection to gather more information.
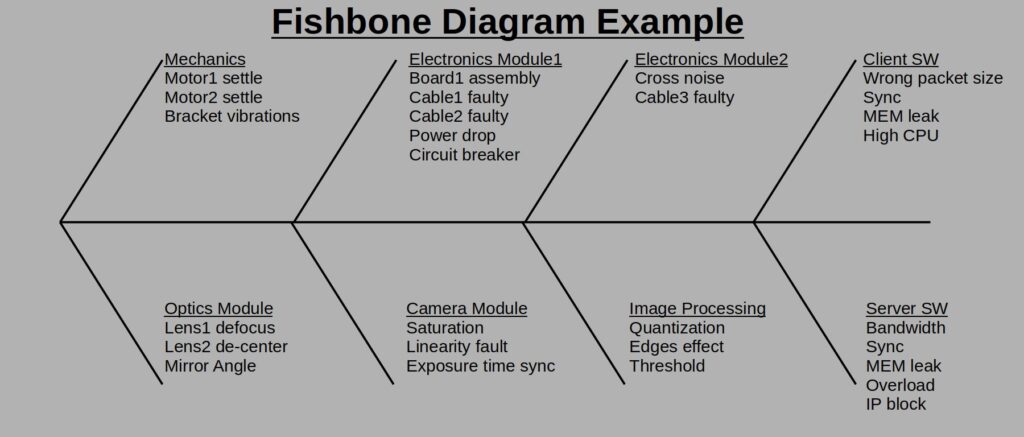
The output of this step would be something like a list or a fishbone diagram of potential root causes.
A fishbone is an engineering tool that allows us to view all possible root causes for our problem in one view. Each stem represents a topic or a family of some kind and the lines coming out of the stem are the detailed different root causes. The diagram is called a fishbone because of its resemblance to, well, a fishbone ![]() .
.
During the troubleshooting process, it is important to update the fishbone with colors such that the status of the process will be visible and easily grasped and so allowing quick understanding of how much is already covered and what are the current suspects and how many more options we consider as possible, see following diagram:
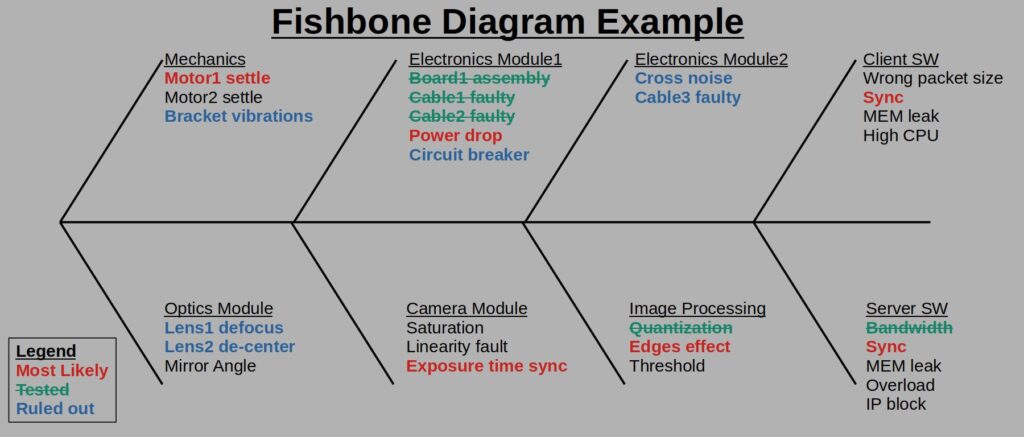
As long as you manage to view the information you wanted, you may play as you like with this diagram type.
4. Solution Action Plan
Once we have the potential root causes from step #3 we may start thinking up solutions. Solutions will be categories into 3: short-term (evolution of the patch in step #1.5), mid-term and long-term.
Short-term solution is another name for a well devised patch. We know it would not be the solution that will go into the next system version but it will, hopefully, hold until the next version is ready for distribution.
Mid-term solution is an interim version that will be distributed only to fix this current particular problem and may not be fully distributed to all clients in the case of an in-the-field problem.
Long-term solution is the solution that will be implemented from now on.
BTW, if the problem happens in a very specific scenario, a solution may also be preventing the client from using the system in that scenario until fixed.
Action plan should take into account available resources, implementation time, complexity of the solution and client involvement. If we have a lovely solution for an urgent problem that will take a year to implement, we’d probably be forced to save it to the long-term solution. Do not be tempted into great solutions when there are no resources available to implement them, prove their validity or integrate them.
When doing an action plan for solutions we should have more than a single action plan as a contingency in case we got it wrong in our most likely causes list. I must admit that this is sometimes difficult as we tend to direct all our forces towards the most likely cause and solution.
Note that in this discussion a “version” is not necessarily SW version – it could be HW, SW, system or even just operation instructions.
5. Testing
A verified root cause is a cause for a problem that we could isolate and have some kind of a tested solution for it. Without a tested solution we could never know if the root cause we agreed upon is indeed the cause of our problem.
Testing the solution is simply implementing a solution and see that the problem is eliminated as expected. AS EXPECTED! The solution is not viable if it introduces other unexpected problems!
The testing is divided into two: in-house and, if relevant, in-the-field. In those extreme cases where the problem could not be reproduced in-house the testing is relevant only in-the-field, however it does not exempt us from initially testing the solution in-house to verify that we have not caused other unexpected issues with this solution.
If the testing of a solution does not end up with the desired results we go back to the next solution item on the list. When we’ve finished the action plan without a successfully tested solution, we have to go back to our original potential causes in step #3 to see what we’ve missed.
6. Implementation
Once we have tested the solution and verified that it works, the implementation should come automatically like any other feature: insert the solution to future generations, fix existing products (or not, if the Product management decides so) and of course – document everything!
This is not just another feature you are required to document. If the problem returns either because the solution was not full or because somehow the solution was not implemented, we may continue the process from where we’ve last stopped and not do the whole investigation from scratch.
Troubleshooting Team – Core Team and Extended Team
Like every process we manage, the attendance list may be the difference between a successful process and an unsuccessful one. When the problem at hand is a power shutdown in the system, we’d better have the electronics team on board right from the beginning but as the root cause becomes more and more complicated to identify the different technical disciplines are necessary and quite often you find yourself managing 15 participants work meetings. In my opinion a working meeting should not have more than 5-6 participants simply because there is not enough time for so many opinions in a standard timeslot of 30-60 minutes.
When there are too many people in the meeting one of two things usually happens; either the meeting becomes a review led by the person who initiated the meeting or the meeting becomes a total mess where nobody really knows what’s going on. BTW, I know there are managers who do not agree with this statement.
So how do we choose the team?
Divide and conquer
Have two separate teams listed for the process: the core team which includes only the ones that get working action items and have data to present; and the extended team which includes all the need-to-know personnel.
Keep every working meeting small and productive with clear agenda (for example, do not start solving other problems in the same meeting). Brainstorming meetings may include a wider attendance list however allow yourself a longer timeslot in the calendar to allow everyone the chance to share their opinion.
Managers? You will get your dedicated update immediately after the core team meeting, or via summary E-mail. Not enough, no problem – set a periodical update meeting for everyone in the extended team. Just remember that it’ll be a review and not a working meeting which means, that you, as the problem owner, will get all the AIs to be dealt with later with the core team. BTW, come prepared! It’s better to delay the update meeting a bit than to come unprepared and waste everyone’s time in the extended team.
We, of course, do not work in a void. The more urgent and impactful the problem is the more pressure you will get from the top brass to involve certain people in the troubleshooting process or in other words, the team personnel is not always up to us, but when it is, keep it as productive as possible.
Consult with the Elders is always a good idea
The senior engineers and architects are referred to as “senior” and “architects” because of their mileage in the business. It usually comes with their share of solved and unsolved problems they managed. Their memory of past issues and troubleshooting process is a gold mine! Just make sure you are on the same page and the advice you get does not involve a product that does not exist anymore ![]() . In terms of teams, having at least one senior in the core team and a bunch of them in the extended team is a must in my opinion.
. In terms of teams, having at least one senior in the core team and a bunch of them in the extended team is a must in my opinion.
To sum up, running a smooth troubleshooting process is an important aspect of any engineering field and especially in System Engineering. I hope you will get your troubleshooting procedures straightened out after reading this post. And above all, I hope you will not need to use these procedures in your professional lives!